Pandas¶
Questo tutorial con i relativi dataset è preso dalla pagina https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/, a cui rimando per eventuali approfondimenti.
Introduzione - Librerie¶
Una libreria, in python come in molti altri linguaggi, è un blocco composto da uno o più file che contengono variabili, funzioni o classi utili, spesso riferite ad un argomento. Una delle piu comuni è la libreria math, che contiene diverse funzioni o costanti matematiche non automaticamente presenti in python. Il motivo per cui tutte queste istruzioni non sono presenti normalmente in python è che lo appesantirebbero inutilmente, ma non appena uno ne ha bisogno può comunque recuperarle facilmente.
Ci sono diverse sintassi per importare una libreria:
import math
print(math.e)
whos
Come vedete, con import NomeLibreria si importa la libreria, che viene poi utilizzata con la sintassi NomeLibreria.funzione o variabile o classe.
Possiamo anche usare delle abbreviazioni:
del math
import math as mt
print(mt.e)
Da ora in poi la libreria non si chiamerà math ma mt. Spesso non abbiamo bisogno di un'intera libreria, ma solo di alcune funzioni. Dobbiamo allora usare un'altra sintassi:
del mt
from math import e, log
print(e)
print(log(e))
mt.e
Come vedete in questo secondo caso non dobbiamo più richiamare nomelibreria.funzione, ma basta il nome della funzione. Se si importano diverse librerie bisogna fare attenzione ad evitare le ambiguità. Possiamo, con questa seconda sintassi, ottenere anche il risultato della precedente importando tutto con *:
from math import *
print(e)
Per l'utilizzo che ne faremo noi, non incontreremo mai problemi di import e conflitti. Chi fosse interessato ad approfondire può trovare ulteriori informazioni al link https://realpython.com/absolute-vs-relative-python-imports/ o sulle guide ufficiali (che però spesso sono un po' macchinose e tecniche su questi argomenti).
Pandas¶
Le pandas, dall'inglese panel data, sono delle librerie molto utilizzate in data science. Servono principalmente ad organizzare e 'pulire' i dati (campi formattati male, record incompleti ecc.), e ci permettono di farne una prima analisi: possiamo ad esempio calcolare la media di un valore o filtrare sui vari campi. È una specie di excel di python.
Installazione e import¶
Per importare le pandas diamo il comando
import pandas as pd
Se ricevete un errore perchè non le avete ancora installate potete, da terminale, digitare:
conda install pandas
o
pip3 install pandas
oppure eseguire la seguente riga:
!pip3 install pandas
Il ! farà eseguire questa riga al terminale.
Componenti base: Series e DataFrames¶
I componenti principali delle pandas sono le Series e i DataFrame.
Una Series è sostanzialmente una colonna, e un DataFrame una tabella fatta di series.
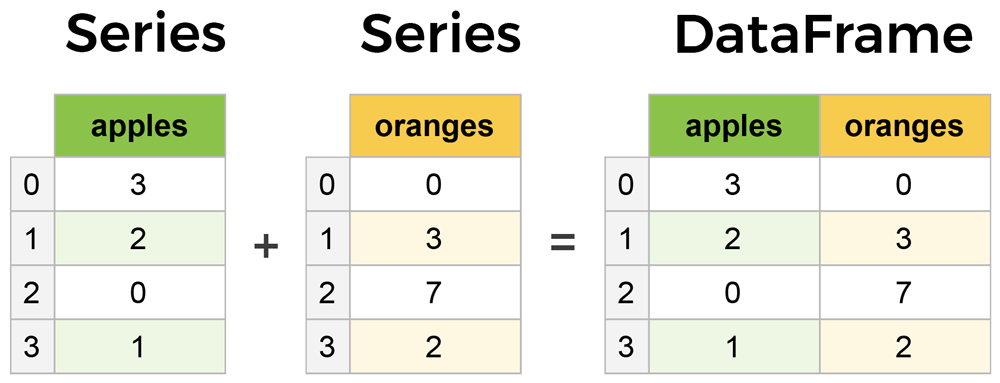
Il modo più semplice di creare un DataFrame è attraverso un dizionario:
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
purchases = pd.DataFrame(data)
purchases
Ogni coppia (chiave,valore) è stata trasformata in (nome colonna, colonna). I dati sono stati indicizzati con i numeri da 0 a 3 (la prima colonna a sinistra) ma possiamo anche definire una nostra indicizzazione con l'opzione index:
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David'])
purchases
Adesso possiamo accedere ai dati che riguardano un singolo indice (ad esempio gli acquisti di June) con il comando loc:
purchases.loc['June']
La sintassi è simile a quella dei dizionari, dove tra parentesi quadre va l'indice.
Leggere dati¶
Nella maggior parte dei casi, comunque, non dovremo essere noi a creare dati, ma avremo grossi file da inserire in un DataFrame. Vediamo come farlo con i file .csv (sostanzialmente dei file di testo che rappresentano tabelle dove le righe sono separate dall'andare a capo e le colonne da virgole o punti e virgola; è il formato standard per trasferire grossi dataset). La stessa cosa si applica sostanzialmente nello stesso modo a file excel (che possono essere importati direttamente, oppure excel permette di esportare csv), json (formato dei dati web), o diversi tipi di database (in python si usa spesso sqlitedb).
Apriamo il file 'purchases.csv', contenente gli stessi dati di sopra.
df = pd.read_csv('purchases.csv')
df
Come vedete la colonna 0 del nostro file non ha un nome, viene quindi salvata come Unnamed; l'indice invece è come sempre assegnato in automatico con numeri da 0 a 3. Noi però vogliamo che la colonna 0 sia letta come indice (in questo caso siamo fortunati, spesso i dataset non hanno questo tipo di indicizzazione quindi non ha senso cercarla):
df = pd.read_csv('purchases.csv', index_col=0)
df
Possiamo facilmente fare l'operazione opposta con il comando to_csv:
df.to_csv('new_purchases.csv')
Operazioni con i DataFrame¶
Vediamo ora le principali operazioni che si possono fare con un DataFrame. Utilizzeremo il dataset IMDB-Movie-Data.csv, che trovate sul sito insieme alla lezione.
movies_df = pd.read_csv("IMDB-Movie-Data.csv", index_col="Title")
In questo caso usiamo la colonna 'title' come indice.
Per vedere le prime righe del dataset usiamo la funzione .head().
movies_df.head(3)
.head(n) accetta un numero come input, e restituisce le prime n righe del nostro dataset. Se non mettiamo niente restituirà le prime 5. Allo stesso modo si comporta la funzione .tail(), che restituisce le ultime righe.
movies_df.tail()
Questo ci serve per farci un'idea. Potete vedere come title sia più in basso degli altri nomi, ad indicare che si tratta dell'indice. Un'altra funzione utile è .info(), che ci riassume le caratteristiche del dataset:
movies_df.info()
Vediamo, ad esempio, che metascore e revenue hanno dei campi vuoti. Un altro comando utile è il comando .shape(), che ci indica la dimensione del dataset.
movies_df.shape
Abbiamo poi un modo comodo di rimuovere i duplicati. Questo dataset non ne ha, quindi creiamone artificialmente:
temp_df = movies_df.append(movies_df)
temp_df.shape
La funzione .append(), a differenza delle liste, non modifica il dataset originale ma ne ritorna uno nuovo. Il nostro temp_df ora ha 2000 righe, corrispondenti a due volte quello originale.
temp_df = temp_df.drop_duplicates()
temp_df.shape
Come vedete, drop_duplicatest() ha cancellato le righe doppie. Anche questa funzione ritorna un nuovo DataFrame, anche se con l'opzione inplace=True possiamo modificare quello iniziale. Un'altra opzione utile è la keep, che permette di tenere alcuni duplicati.
Con il comando .columns otteniamo le colonne del nostro dataset:
movies_df.columns
I nomi delle colonne possono essere modificati sia con il comando .rename(), che con l'accesso diretto:
movies_df.rename(columns={
'Runtime (Minutes)': 'Runtime',
'Revenue (Millions)': 'Revenue_millions'
}, inplace=True)
movies_df.columns
movies_df.columns = ['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore']
movies_df.columns
movies_df.columns = [col.lower() for col in movies_df]
movies_df.columns
Abbiamo a disposizione anche il comando isnull(), che restituisce un nuovo DataFrame in cui tutti i campi sono True se erano vuoti e False se invece erano pieni. Facendo la somma per colonne (con sum()) possiamo vedere quanti campi sono vuoti all'inizio.
movies_df.isnull().head()
movies_df.isnull().sum()
Le righe con valori nulli possono essere cancellati con dropna(), che restituisce un nuovo DF senza modificare l'originale. Questa opzione però è spesso sconsigliata, e va valutata bene a seconda dei dati:
movies_df.dropna().size
Con il seguente codice, che sarà più chiaro tra poco, possiamo ad esempio riempire i campi vuoti con la media della colonna:
revenue = movies_df['revenue_millions']
revenue_mean = revenue.mean()
revenue.fillna(revenue_mean, inplace=True)
movies_df.isnull().sum()
revenue è la nostra colonna, revenue_mean la media dei suoi valori, e fillna() è la funzione che si occupa di riempire i vuoti, il primo parametro è il valore che ci va dentro, il secondo indica di modificare il dataset originale.
Con la funzione describe otteniamo alcuni elementari dati statistici sul DF:
movies_df.describe()
Possiamo applicare questa funzione anche ad una sola colonna:
movies_df['genre'].describe()
mentre value_counts() ci restituisce quante volte compaiono i più frequenti nomi in quella colonna.
movies_df['genre'].value_counts().head(10)
Un altro interessante metodo è .corr(), che restituisce la correlazione incrociata tra variabili numeriche;
movies_df.corr()
Per approfondire questi aspetti potete andare al link Essential Statistics for Data Science.
Estrazione e selezione dei dati¶
Per colonna¶
genre_col = movies_df['genre']
type(genre_col)
Possiamo accedere ad una colonna, come abbiamo già visto, indicando il suo nome tra parentesi quadre dopo il nome del DF. Questo restituisce una Series. Se invece di un nome usiamo una lista otteniamo un sotto-dataframe con solo le colonne indicate:
subset = movies_df[['genre', 'rating']]
subset.head()
genre_col = movies_df[['genre']]
type(genre_col)
Ovviamente possiamo usare una lista di un elemento per ottenere un dataframe di una sola colonna.
Per righe¶
Per le righe abbiamo due opzioni:
.loc- estrae la riga con l'indice richiesto.iloc- estrae la riga con l'indice numerico richiesto
prom = movies_df.loc["Prometheus"]
prom
prom = movies_df.iloc[1]
prom
loc e iloc si comportano come le liste per quanto riguarda lo slicing:
movie_subset = movies_df.loc['Prometheus':'Sing']
movie_subset = movies_df.iloc[1:4]
movie_subset
Selezione Condizionale¶
Una sintassi un po' strana ma fondamentale ci permette anche di selezionare righe in base ad una condizione. Applicando un'operazione booleana ad un df otteniamo un nuovo df con True al posto delle righe che la soddisfano, False nelle altre (come con isnull()).
condition = (movies_df['director'] == "Ridley Scott")
condition.head()
Se passiamo questo 'DataFrame Booleano' al posto di un indice, otteniamo un df filtrato dalla nostra condizione:
movies_df[movies_df['rating'] >= 8.6].head(3)
In questo caso però, le congiunzioni or e and sono sostituite da | e &:
movies_df[(movies_df['director'] == 'Christopher Nolan') | (movies_df['director'] == 'Ridley Scott')].head()
mentre la condizione in diventa isin()
movies_df[movies_df['director'].isin(['Christopher Nolan', 'Ridley Scott'])].head()
Possiamo poi applicare una funzione ad una determinata colonna (ad esempio per crearne una nuova), con la sintassi apply():
movies_df["rating_category"] = movies_df["rating"].apply(lambda x: 'good' if x >= 8.0 else 'bad')
movies_df.head(2)
In questo caso creiamo la nuova riga "rating category", che vale good se il film ha più di 8 come voto, e bad altrimenti.
Approfondimenti¶
In questa introduzione ci siamo occupati degli aspetti fondamentali delle Pandas. Questa libreria è alla base di quasi tutta la data science moderna, e contiene diversi potenti strumenti. Per chi volesse approfondire, ci sono molti validi tutorial sul sito ufficiale. Per vedere invece cosa la gente seria fa con pandas e altre cose, fate un salto sul sito Kaggle: troverete notebook di data science e machine learning di alto livello (ovviamente non siamo ancora in grado di capire quasi tutto quello che c'è, però vi può dare un'idea delle potenzialità di questi strumenti. A questo link trovate una guida specifica su come rimpiazzare excel con le pandas, per chi fosse particolarmente abituato ad usarlo.
Un altro aspetto delle pandas, che apprezzeremo meglio nelle prossime settimane, è che questa libreria è costruita per integrarsi perfettamente con i principali strumenti di analisi dati presenti nello sci-kit di python (pyplot, sklearn...)
Esercizi¶
Provate a:
- Selezionare solo i film prodotti tra il 2010 e il 2015 con un voto superiore all'8
- Creare una nuova colonna che indichi un film come 'lungo' se dura più di due ore, 'corto' se dura meno